- Перевод
- Tutorial
Надо “ SELECT * WHERE a=b FROM c ” или “ SELECT WHERE a=b FROM c ON * ” ?
Если вы похожи на меня, то согласитесь: SQL - это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:


У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” - имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title FROM books WHERE author="Dan Brown";
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM - откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE - какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк , которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author - это “Dan Brown”.
3.3 SELECT - как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid=books.bookid WHERE books.author="Dan Brown";
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы . Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице , которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid - это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 - откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid
Результат соединения можно увидеть по ссылке .
Шаг 2 - какие данные показываем? Нас интересуют только те данные, где автор книги - “Dan Brown”
WHERE books.author="Dan Brown"
Шаг 3 - как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown";
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну . При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count(*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown" GROUP BY members.firstname, members.lastname;
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT "ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock) FROM books GROUP BY author;
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов - использовать подзапросы:
SELECT * FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE author="Robin Sharma";
Результат:
Можно записать как: ["Robin Sharma", "Dan Brown"]
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3);
Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown");
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;
Что дает нам:
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT "ом, мы задаем знаения SET "ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books SET stock=0 WHERE author="Dan Brown";
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books WHERE author="Dan Brown";
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
INSERT INTO x (a,b,c) VALUES (x, y, z);
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
INSERT INTO books (bookid,title,author,published,stock) VALUES (1,"Scion of Ikshvaku","Amish Tripathi","06-22-2015",2), (2,"The Lost Symbol","Dan Brown","07-22-2010",3), (3,"Who Will Cry When You Die?","Robin Sharma","06-15-2006",4), (4,"Inferno","Dan Brown","05-05-2014",3), (5,"The Fault in our Stars","John Green","01-03-2015",3);
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Теги: Добавить метки
Объединение таблиц.
В запросе можно объединять данные из одной или нескольких таблиц. Такое объединение таблиц называется соединением (связыванием) таблиц. Различают внутреннее и внешнее соединения.
Внутреннее соединение – это соединение, при котором результирующий набор получается путем перечисления нужных полей из разных таблиц после слова SELECT. При этом таблицы должны находиться в отношении «один-к-одному».
Например,
SELECT R.fam, R.birthday,A.Foto
FROM Rabotniki R, Advanced A
где таблицы Rabotniki и Advanced содержат основные и дополнительные сведения о работниках предприятия. Связь «один-к-одному». Таблице Rabotniki дан псевдоним R, а таблице Advanced дан псевдоним A.
В предыдущем примере перед именем поля записано имя таблицы. Имена поля и таблицы отделяются точкой. Имя таблицы указывать необходимо, если имена полей повторяются для различных таблиц.
Если применить внутреннее соединение к таблицам, связанным по принципу «один-ко-многим», то результирующий набор может содержать избыточную информацию. Для устранения избыточности используют критерии отбора.
Пример 1 . Дана БД Sotrudniki, состоящая из двух таблиц:
Запрос внутреннего соединения таблиц, связанных отношением «один-ко-многим» имеет вид
Число записей в результирующем наборе данных равно произведению числа записей в таблице Sotrudniki на число записей в таблице Doljn. Результирующий набор данных имеет вид и содержит избыточную информацию:

Для ограничения числа записей в результирующем наборе данных применяют критерии отбора. Запрос в этом случае будет иметь вид
SELECT S_Fio,S_Birthday,D_Nazv FROM Sotrudniki, Doljn
WHERE S_Doljn=D_Code
Число записей в результирующем наборе данных будет равно числу записей в таблице Sotrudniki. p
Пример 2 . Требуется для БД Sotrudniki сформировать запрос, который позволит получить список сотрудников, имеющих должность «программист». Получим
SELECT S_fio, S_birthday FROM sotrudniki, doljn
WHERE S_doljn=D_code and D_nazv="программист"
В SQL-запросах допускается самообъединение таблицы. В этом случае одной таблице даются два псевдонима.
Например, для нахождения всех ровесников в таблице Sotrudniki можно написать запрос:
SELECT s1.s_fio, s2.s_fio, s1.s_birthday
FROM Sotrudniki s1, Sotrudniki s2
WHERE (EXTRACT(YEAR
FROM s1.s_birthday)=EXTRACT(YEAR
FROM s2.s_birthday))
AND (s1.s_fio!=s2.s_fio) AND (s1.s_fio Последнее условие упорядочивает фамилии и исключает дублирование результатов. При внутреннем соединении все таблицы, поля которых указаны в SQL-запросе, являются равноправными. То есть каждой записи в первой таблице находилась соответствующая ей запись во второй таблице. При внешнем объединении
(outer join
) в результирующий набор включаются записи независимо от того, есть ли соответствующее поле во второй таблице. Существует три типа внешнего объединения. 1) LEFT OUTER JOIN … ON –
левое, включает в результат все записи первой таблицы, даже те, для которых не имеется соответствия во второй. 2) RIGHT OUTER JOIN … ON
– правое, включает в результат все записи второй таблицы, даже те, для которых не имеется соответствия в первой. 3) FULL OUTER JOIN … ON
– полное, включает в результат объединение записей обеих таблиц, независимо от их соответствия. При внешнем соединении можно говорить о том, какая из таблиц является главной. В первом случае – левая, во втором – правая. Например.
Пусть в таблице Sotrudniki БД Sotrudniki есть фамилии, имеющие должность, не указанную в таблице Doljn, и есть должности в таблице Doljn, для которых нет фамилии в таблице Sotrudniki. Тогда 1) SELECT * FROM Sotrudniki LEFT OUTER JOIN Doljn ON S_doljn=D_code Результат включат все поля и таблицы Sotrudniki и таблицы Doljn. Число строк соответствует числу записей таблицы Sotrudniki. В строках, относящихся к записям, для которых в Doljn не нашлось соответствие, поля таблицы Doljn остаются пустыми. 2) SELECT * FROM Sotrudniki RIGHT OUTER JOIN Doljn ON S_doljn=D_code Число строк соответствует числу записей таблицы Doljn. В строках, относящихся к записям, для которых в Sotrudniki не нашлось соответствие, поля таблицы Sotrudniki остаются пустыми. 3) SELECT * FROM Sotrudniki FULL OUTER JOIN Doljn ON К строкам, относящимся к таблице Sotrudniki добавлены строки, относящиеся к таблице Doljn, для которых нет соответствия в таблице Sotrudniki. В SQL-запросе можно использовать запросы, вложенные в первый. Это можно применить и к операторам, возвращающих совокупные характеристики, и к операторам, возвращающим множество значений. Например, 1) Определить всех однофамильцев в таблицах Sotrudniki и Sotrudniki1, имеющих одинаковую структуру: SELECT * FROM Sotrudniki WHERE S_fio IN (SELECT S_fio FROM Sotrudniki1) Вложенный оператор SELECT возвращает множество фамилий из таблицы Sotrudniki1, а конструкция WHERE основного оператора SELECT отбирает в таблице Sotrudniki те записи, которые имеются во множестве фамилий из таблицы Sotrudniki1. 2) Вывести из БД Sotrudniki фамилию (фамилии) самого молодого сотрудника: SELECT S_Fio, EXTRACT(YEAR FROM S_Birthday) WHERE EXTRACT(YEAR FROM S_Birthday)= (SELECT max(EXTRACT(YEAR FROM S_Birthday)) FROM Sotrudniki) Вложенный оператор SELECT возвращает максимальный год рождения, который используется в условии WHERE основного оператора SELECT. 3) Вывести из БД Students все оценки конкретного студента, например, Петрова: SELECT S_fam, P_nazv, E_mark FROM Examination,Predm, Students WHERE E_student=(SELECT S_code FROM Students WHERE S_fam="Петров") AND E_Predm=P_code AND E_Student=S_code Во вложенной конструкции SELECT определяется код студента по фамилии "Петров", а последние условия обеспечивают исключение избыточности при внутреннем объединении таблиц. Связанные подзапросы.
Во внутреннем запросе можно ссылаться на таблицу, имя которой указано в предложении FROM
внешнего запроса. Такой связанный
подзапрос выполняется по одному разу для каждой строки таблицы основного запроса. Например,
получить сведения о предметах, по которым проводился экзамен конкретного числа, например, ‘14.01.2006’: SELECT * FROM Predm PR WHERE "14.01.2006" IN (SELECT E_date FROM Examination WHERE PR.P_code=E_predm) Эту же задачу можно решить с помощью операции соединения таблиц: SELECT DISTINCT P_nazv FROM Predm, Examination WHERE P_code=E_predm AND E_date= "14.01.2006" Пример.
Вывести фамилию (фамилии) студента, получившего на экзамене оценку выше среднего балла SELECT DISTINCT S_fam FROM Students, Examination E_mark>(SELECT AVG(E_mark) FROM Examination) AND S_code=E_student В условии WHERE при работе с множествами записей можно использовать ключевые слова ALL
и ANY. ALL
- условие выполняется для всех записей, ANY
- условие выполняется хотя бы для одной записи. Например
,
1) вывести фамилии сотрудников из таблицы Sotrudniki, которые не старше любого сотрудника в таблице Sotrudniki1: WHERE S_birthday>= ALL (SELECT S_birthday FROM Sotrudniki1) 2) вывести фамилии сотрудников из таблицы Sotrudniki, которые моложе хотя бы одного сотрудника в таблице Sotrudniki1: SELECT S_fio,S_birthday FROM Sotrudniki WHERE S_birthday> ANY (SELECT S_birthday FROM Sotrudniki1) Во вложенных конструкциях SELECT можно использовать ключевое слово EXISTS,
которое означает отбор только тех записей, для которых вложенный запрос возвращает одно или более значений. Например,
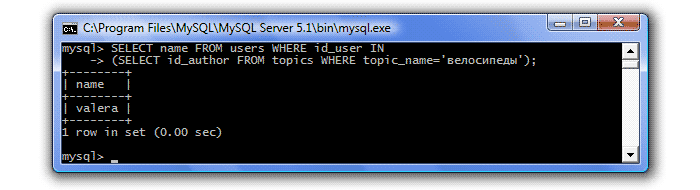
SELECT S_fio,S_birthday FROM Sotrudniki S1 WHERE EXISTS (SELECT S_fio,S_birthday FROM Sotrudniki S2 WHERE (S1.S_birthday=S2.S_birthday) AND (S1.S_code!=S2.S_code)) Получение списка сотрудников, которые имеют хотя бы одного сверстника. В прошлом уроке мы столкнулись с одним неудобством. Когда мы хотели узнать, кто создал тему "велосипеды", и делали соответствующий
запрос:
Вместо имени автора, мы получали его идентификатор. Это и понятно, ведь мы делали запрос к одной таблице - Темы, а имена авторов
тем хранятся в другой таблице - Пользователи. Поэтому, узнав идентификатор автора темы, нам надо сделать еще один запрос -
к таблице Пользователи, чтобы узнать его имя:
В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос).
Итак, чтобы узнать, кто создал тему "велосипеды", мы сделаем следующий запрос: То есть, после ключевого слова WHERE
, в условие мы записываем еще один запрос. MySQL сначала обрабатывает
подзапрос, возвращает id_author=2, и это значение передается в предложение WHERE
внешнего запроса. В одном запросе может быть несколько подзапросов, синтаксис у такого запроса следующий:
Обратите внимание, что подзапросы могут выбирать только один столбец, значения которого они будут возвращать внешнему запросу.
Попытка выбрать несколько столбцов приведет к ошибке. Давайте для закрепления составим еще один запрос, узнаем, какие сообщения на форуме оставлял автор темы "велосипеды": Теперь усложним задачу, узнаем, в каких темах оставлял сообщения автор темы "велосипеды": Давайте разберемся, как это работает.
SQL позволяет вкладывать запросы друг в друга. Обычно подзапрос возвращает одно значение, которое проверяется на предмет истинности предиката. Виды условий поиска:
Примечания по вложенным запросам:
Примеры на вложенные запросы
: SELECT * FROM Orders WHERE SNum=(SELECT SNum FROM SalesPeople WHERE SName=’Motika’) В SQL можно создавать подзапросы со ссылкой на таблицу из внешнего запроса. В этом случае подзапрос выполняется многократно, по одному разу для каждой строки таблицы из внешнего запроса. Поэтому важно, чтобы подзапрос использовал индекс. Подзапрос может обращаться к той же таблице, чтоб и внешний. Если внешний запрос возвращает относительно небольшое число строк, то связанный подзапрос будет работать быстрее несвязанного. Если подзапрос возвращает небольшое число строк, то связанный запрос выполнится медленнее несвязанного. Примеры на связанные подзапросы:
SELECT * FROM SalesPeople Main WHERE 1(SELECT AVG(Amt) FROM Orders O2 WHERE O2.CNum=O1.CNum) //возвращает все заказы, величина которых превосходит среднюю величины заказа для данного покупателя Синтаксическая форма: EXISTS
() Предикат использует подзапрос в качестве аргумента и оценивает его как истинный, если в подзапросе есть выходные данные, а в противном случае как ложный. Выполняется подзапрос один раз и может содержать несколько столбцов, поскольку их значения не проверяются, а просто фиксируется результат наличия строк. Примечания по предикату EXISTS:
Примеры на предикат EXISTS:
SELECT * FROM Customer WHERE EXISTS(SELECT * FROM Customer WHERE City=’San Jose’) – возвращает всех покупателей, если кто-то из них проживает в San Jose. Синтаксическая форма: {=|>|=|} ANY|ALL
() Эти предикаты используют в качестве аргумента подзапрос, однако, по сравнению с предикатом EXISTS, они применяются в конъюнкции с предикатами отношения (=,>=). В этом смысле они сходны с предикатом IN, но применяются только с подзапросами. Стандарт допускает использовать вместо ANY ключевое слово SOME, однако не все СУБД его поддерживают. Примечания по предикатам сравнения:
Примеры на предикат количественного сравнения:
SELECT * FROM SalesPeople WHERE City=ANY(SELECT City FROM Customer) UNIQUE|DISTINCT
() Предикат служит для проверка уникальности (отсутствия дублей) в выходных данных подзапроса. Причем в предикате UNIQUT строки с NULL значениями считаются уникальными, а в предикате DISTINCT два неопределенных значения считаются равными друг другу. MATCH
() Предикат MATCH проверяет, будет ли значение строки запроса совпадать со значением любой строки, полученной в результате подзапроса. От предикатов IN И ANY такой подзапрос отличается тем, что позволяет обрабатывать «частичные» (PARTIAL) совпадения, которые могут встречаться среди строк, имеющих часть NULL-значений. Фактически допустимо использовать подзапрос везде, где допускается ссылка на таблицу. SELECT CName, Tot_Amt FROM Customer, (SELECT CNum, SUM(Amt) AS Tot_Amt FROM Orders GROUP BY CNum) WHERE City=’London’ AND Customer.CNum=Orders.CNum WITH RECURSIVE



Вот собственно и все, что хотелось сказать о вложенных запросах. Хотя, есть два момента, на которые стоит обратить внимание:
написать
Т.е. мы можем использовать любые операторы, используемые с ключевым словом WHERE (их мы изучали в прошлом уроке).
. Сравнение с результатом вложенного запроса (=, >=)
. Проверка на принадлежность результатам подзапроса (IN)
. Проверка на существование (EXISTS)
. Многократное (количественное) сравнение (ANY, ALL)
. Подзапрос должен выбирать только один столбец (за исключением подзапроса с предикатом EXISTS), и тип данных его результата должен соответствовать типу данных значения, указанному в предикате.
. В ряде случаев можно использовать ключевое слово DISTINCT для гарантии получения единственного значения.
. Во вложенном запросе нельзя включать раздел ORDER BY и UNION.
. Подзапрос может находиться и лева и справа от условия поиска.
. В подзапросах могут использоваться функции агрегирования без раздела GROUP BY, которые автоматически выдают специальное значение для любого количества строк, специальный предикат IN, а также выражения, основанные на столбцах.
. По возможности следует вместо подзапросов использовать соединение таблиц JOIN.
SELECT * FROM Orders WHERE SNum IN (SELECT SNum FROM SalesPeople WHERE City=’London’)
SELECT * FROM Orders WHERE SNum=(SELECT DISTINCT SNum FROM Orders WHERE CNum=2001)
SELECT * FROM Orders WHERE Amt>(SELECT AVG(Amt) FROM Orders WHERE Odate=10/04/1990)
SELECT * FROM Customer WHERE CNum=(SELECT SNum+1000 FROM SalesPeople WHERE SName=’Serres’)2) Связанные подзапросы
3) Предикат EXISTS
. EXISTS – предикат, возвращающий значение TRUE или FALSE, и его можно применять отдельно или вместе с другими булевыми выражениями.
. EXISTS не может использовать функции агрегирования в своем подзапросе.
. В коррелирующих (связанных, зависимых – Correlated) подзапросах предикат EXISTS выполняется для каждой строки внешней таблицы.
. Можно комбинировать предикат EXISTS с соединениями таблиц.
SELECT DISTINCT SNum FROM Customer First WHERE NOT EXISTS (SELECT * FROM Customer Send WHERE Send.SNum=First.SNum AND Send.CNumFirst.CNum) – возвращает номера продавцов, обслуживших только одного покупателя.
SELECT DISTINCT F.SNum, SName, F.City FROM SalesPeople F, Customer S WHERE EXISTS (SELECT * FROM Customer T WHERE S.SNum=T.SNum AND S.CNumT.CNum AND F.SNum=S.SNum) – возвращает номера, имена и города проживания всех продавцов, обслуживших нескольких покупателей.
SELECT * FROM SalesPeople Frst WHERE EXISTS (SELECT * FROM Customer Send WHERE Frst.SNum=Send.SNum AND 14) Предикаты количественного сравнения
. Предикат ALL принимает значение TRUE, если каждое значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Предикат ANY принимает значение TRUE, если хотя бы одно значение, выбранное в процессе выполнения подзапроса, удовлетворяет условию, заданному в предикате внешнего запроса. Чаще всего он используется с неравенствами.
. Если подзапрос не возвращает строк, то ALL автоматически принимает значение TRUE (считается, что условие сравнения выполняется), а для ANY – FALSE.
. Если сравнение не имеет значения TRUE ни для одной строки и есть одна или несколько строк с NULL значением, то ANY возвращает UNKNOWN.
. Если сравнение не имеет значения FALSE ни для одной строки и есть одна или несколько строк с NULL значением, то ALL возвращает UNKNOWN.
SELECT * FROM Orders WHERE Amt ALL(SELECT Rating FROM Customer WHERE City=’Rome’)5) Предикат уникальности
6) Предикат совпадений
7) Запросы в разделе FROM
//подзапрос возвращает суммарную величину заказов, сделанных каждым покупателем из Лондона.8) Рекурсивные запросы
Q1 AS SELECT … FROM … WHERE …
Q2 AS SELECT … FROM … WHERE …





